
티스토리 뷰
요구사항
- 유저는 지인들과 그룹을 만들 수 있으며, 그룹 내에서 서로 어느 위치에 있는지 휴대폰 화면으로 확인할 수 있어야 한다.
- 특히나, 두 명 이상의 유저가 가까운 거리에 있는 경우 느리게 업데이트되면 빠르게 위치를 파악하지 못해 만나는데 서비스가 크게 도움이 되지 않을 것이기에 3초에 한 번 자신의 위치를 클라이언트에서 공유하여 그룹 전체 인원에게 알린다.
문제 상황 - 실시간 공유 기술 선택
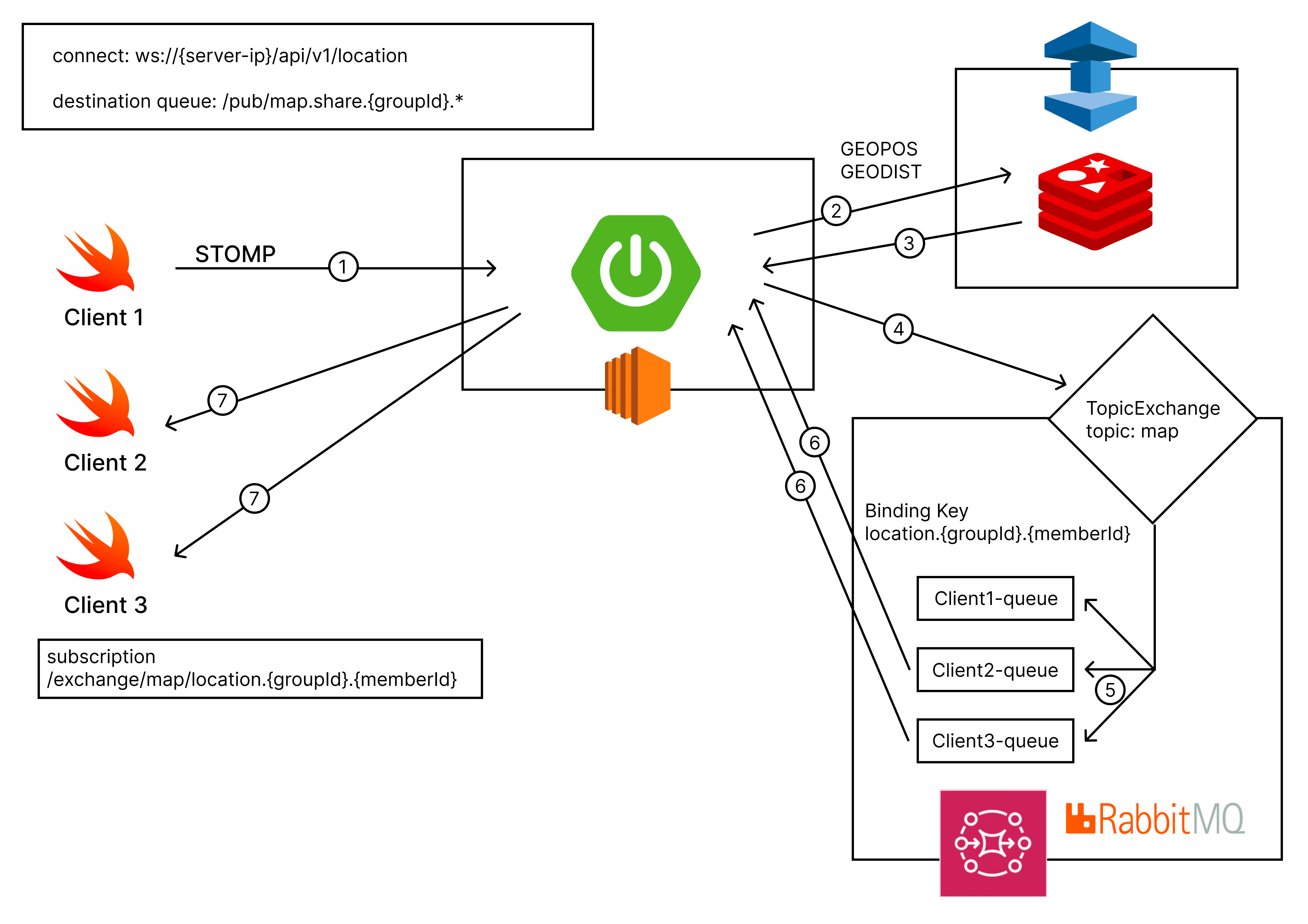
- 양방향 실시간 위치 공유 구현을 위한 기술 선택 필요
- 요구 사항
- [실시간성] 실시간으로 데이터 변경 시 신속히 클라이언트에서 확인 가능해야 함
- 변화 시점마다 그룹원의 위치 파악 필요
- [양방향 지원] 양방향으로 데이터를 공유
- 각 그룹원이 데이터를 서버에 보내면 나머지 그룹원이 데이터 받아야 함
- [높은 업데이트 빈도] 각 유저는 3초 주기로 데이터를 공유하며 각각 다른 시점에 공유
- STOMP 연결 시점부터 공유 시작하여 3초 주기 반복
- [실시간성] 실시간으로 데이터 변경 시 신속히 클라이언트에서 확인 가능해야 함
기술 실시간성 양방향 지원 높은 업데이트 빈도
| 기술 | 실시간성 | 양방향 지원 | 높은 업데이트 빈도 |
| Websocket | 적합 | 적합 | 적합 |
| API Short 폴링 | 폴링 주기에 의존적 | 적합 | 부하가 심함 - 부적합 |
| API Long 폴링 | 준수함 | 적합 | 부하가 심함 - 부적합 |
| Server Sent Event | 적합 | 단방향에 최적 - 부적합 | 적합 |
위 분석과 함께 성능테스트를 진행하였으며, 타 포스트(글의 최하단 링크 참고)에 기술하였다.
- Websocket이 적합해 보였으며 애매한 부분을 성능테스트를 통해 확인하며 정해진 통신 형식 사용 가능한 STOMP 선택
의문과 고민
- 실시간 양방향 위치 공유를 구현하기 위해 위와 같이 STOMP를 선택하여 구현하며 의문이 들었다.
- 간단히 STOMP가 제공하는 Simple Broker를 사용한 부분과, DB에 좌표를 저장하고 자바 코드를 통해 사칙연산으로 좌표 거리를 계산하는 부분이 적합한지 고민하였다.
문제 상황 - 구현과 기술 선택
- 설계 단계에서 서버의 수평적 확장도 고려했지만, 확장성을 고려했을때 Simple Broker는 치명적 단점을 가지고 있다.
- STOMP 제공 Simple Broker는 다중 서버로 확장시 라우팅 문제가 발생한다.
- 서버에 각각 하나의 Simple Broker가 존재하여 같은 그룹원이 서로 다른 브로커를 구독하며 서로 데이터를 받을 수 없는 문제다.
고민
MQ 고민
서비스 요구사항
- 서비스 요구사항에 알맞은 MQ를 고민했다.
- 그룹별로 데이터를 공유해야 하며 평균 4명의 그룹원이 존재 (설계 단계 예상 수치이며, 모임의 인원수다.)
- 그룹원 당 3초 주기로 json 데이터를 공유한다.
- 한 그룹당 평균 1초당 1.3개의 데이터를 지속적으로 처리해야 한다.
- 10000명 즉, 2500개의 그룹이 존재할 때 2500 * 1.3 = 3250 tps를 처리해야 한다.
- 그룹이 많아질 수록 하나의 queue로 처리하기엔 병목 현상 우려 -> queue를 여러개 만드는 것이 효율적
- 그룹별로 데이터를 공유해야 하며 평균 4명의 그룹원이 존재 (설계 단계 예상 수치이며, 모임의 인원수다.)
queue 생성 및 사용 전략 고민과 선택
- [queue를 미리 많이 만들어둔 후 분산시키는 방법 vs queue를 동적으로 만들고 삭제하며 사용하는 방법] 고민
- 그룹별로 데이터를 공유해야 하며, 타 그룹과의 데이터 공유는 필요가 없었다.
- 그룹별로 바인딩을 만드는 방법 고려했다.
- 그룹원은 계속 늘어나기 때문에 동적으로 queue와 binding을 (생성/삭제)하며 사용하면 효율적일 것이라 판단했다.
- 또한, 고려했던 TopicExchange는 binding을 메모리를 많이 사용하는 trie 자료구조에 저장하기 때문에, 계속 binding이 추가됨에 따라 불필요하게 메모리를 지속해서 사용할 수 있어서 제거하지 않으면 문제가 있다고 생각했다.
- RabbitMQ는 이러한 요구사항을 만족했다.
- 연결시 binding, queue가 없으면 생성되고 연결이 모두 끊어지면 자동으로 삭제되도록 구성가능하다.
- 그룹원 별로 연결 요청 시 queue를 생성하며 그룹원 별로 연결 해제 시 queue 제거
- 그룹 내의 첫 연결 요청 시 binding을 생성하며 그룹 내의 마지막 연결 해제 요청 시 binding 제거
- 바인딩이 동적으로 추가되는 복잡한 라우팅 기능 또한 RabbitMQ는 효과적으로 사용할 수 있다.
- 그룹, 그룹원의 DB PK를 기반으로 queue로 라우팅되도록 바인딩을 구성하는 작업이 필요했으며 이에 용이했다.
- 연결시 binding, queue가 없으면 생성되고 연결이 모두 끊어지면 자동으로 삭제되도록 구성가능하다.
- 다른 MQ들은 어떨까
- Redis는 동적으로 생성은 가능하지만 queue(stream)은 삭제할 수는 없고 직접 관리해야 한다. list를 queue와 같이 사용할만큼 메모리를 사용하면서 queue의 데이터를 지속하지 않아도 됐다.
- 또한, pub/sub은 메시지 유실 문제가 있으며 sub 누락 시 지속적으로 데이터를 받지 못하는 경우가 있을 것인데 즉시 알기 어려운 이슈이며 사용자에게 불편함을 줄 수 있다고 판단했다.
- Kafka는 동적으로 queue를 생성/삭제가 가능하지만 대용량 처리를 위해 설계된 만큼 이러한 동적 관리가 권장되지 않는다고 한다.
- 이길저길은 Kafka를 사용해야할 만큼의 메시지 저장이나 대용량 처리를 요구하지 않았다.
- Kafka 또한 클라이언트 연결 종료시 자동 삭제는 불가하여 따로 구현해야 한다.
- 위 두 기술 모두 라우팅 기능이 RabbitMQ 만큼은 아니더라도 어느정도 가능하지만, 확실히 RabbitMQ가 이점이 있으며, 위에 기술한 항목들을 생각해 선택하지 않았다.
- 따라서, RabbitMQ를 선택했다.
- 그룹별로 데이터를 공유해야 하며, 타 그룹과의 데이터 공유는 필요가 없었다.
- RabbitMQ는 STOMP를 플러그인으로 지원하고 라우팅을 제공하는 MQ 중에서도 확장성이 높다는 이점도 챙길 수 있었다.
- 플러그인을 통해 [non-durable, auto-delete] 옵션이 설정된 Topic을 사용했다.
- non-durable: 메모리 상에서만 큐를 사용하며, 메타데이터를 디스크에 저장하는 작업 없이 사용 가능하다.
- 특히나, 큐를 생성/삭제하는 오버헤드가 durable 큐보다 적으며 디스크 I/O 작업 또한 줄어든다.
- 서비스에서 큐의 데이터는 지속성이 크게 요구되지는 않았다. 위치는 다시 연결해서 공유하면 되기 때문이다.
- auto-delete: 모든 연결이 끊어진 경우 자동으로 삭제한다.
- 다른 기술과 달리 따로 모니터링하여 연결이 없는지 확인하며 삭제해주지 않아도 된다.
- non-durable: 메모리 상에서만 큐를 사용하며, 메타데이터를 디스크에 저장하는 작업 없이 사용 가능하다.
- 플러그인을 통해 [non-durable, auto-delete] 옵션이 설정된 Topic을 사용했다.
MQ 아키텍처 관점 고민 (AWS를 사용했기에 다른 클라우드는 배제했다.)
- RabbitMQ용 EC2 인스턴스에 배포 vs 2. 백엔드 서버와 같은 인스턴스에 배포 vs 3. Amazon MQ
- RabbitMQ용 EC2 인스턴스에 배포
- 커스텀하게 설정할 수 있지만, 모든 사항을 직접 관리해야한다.
- 특히 장애 상황에 대응하기 위한 모든 작업을 수동으로 해야한다는 단점이 있다.
- 백엔드 서버와 같은 인스턴스에 배포
- 이 방법은 확장성을 고려했을때 백엔드 서버와 RabbitMQ가 같이 확장되고 수축되어야 한다는 단점이 있다.
- Amazon MQ
- EC2와 같은 컴퓨팅 인스턴스에 RabbitMQ를 올려 사용하는 방법이라 하지만, 다양한 기능을 제공했다.
- 장애 상황에 대응하기에 적합하다.
- EBS 스냅샷을 통해 장애 상황에 데이터를 복구할 수 있다.
- 액티브-스탠바이 구성으로 장애 상황시 미리 준비해둔 인스턴스를 사용가능하다.
- 이 기능은 이후 클러스터링을 구성하게되면 사용해볼 계획이다.
- 평균적으로 토픽당 21000 이상, 큐 당 2000 이상의 tps 처리가 가능해 무리 없이 요구사항을 충족했다.
- 큐 별로 1.3 tps라 가정했을때, 16000개의 큐 즉, 4000개의 그룹을 수용할 수 있기에 요구사항을 상회했다.
- NIO 기반 톰캣을 사용했으며 기본 설정을 건들이지 않은 상태였기에 대략 1만개의 요청을 수용할 수 있다고 가정해도 Amazon MQ는 넉넉한 tps를 제공했다.
- 따라서 Amazon MQ를 사용하기로 결정했다.
- RabbitMQ용 EC2 인스턴스에 배포
좌표 계산 고민 (Redis Geo)
- 요구사항
- 위치 좌표를 STOMP를 통해 보내면 자기 자신의 위치 좌표를 업데이트한다.
- 그룹원 모두의 평균 좌표를 계산한 다음, 해당 좌표까지의 본인 위치에서의 거리를 계산하여 본인의 위치와 함께 거리를 모든 구성원과 본인에게 공유된다.
- DB 사용시 문제점
- 데이터가 많아질 경우 조회를 위해 인덱스를 고려하기 어렵다. 위치 좌표 공유시 매번 데이터가 수정되기 때문이다.
- 디스크 I/O에 의존적일 것이라 예상된다.
- Redis Geo
- 내부적으로 GeoHash와 SortedSet을 사용하기에 조회가 빠르다.
- 간단한 거리 계산 API를 제공한다.
- 따라서, Redis Geo를 사용하기로 결정했다.
- 아키텍처 관점 고민
- EC2를 사용하며 수동으로 관리할 만큼의 유연성이 필요한 요구사항이 있지 않았으며 Elasticache는 관리에 용이한 기능들을 제공했다.
- 인스턴스의 백업이나 장애 대응에 효과적인 기능을 제공했기에 안정적으로 운영할 수 있을 것이라 기대했다.
- 따라서 Elasticache 기반 Redis를 사용하기로 했다.
해결 & 결과
- Redis의 Geo를 사용하여 사용자 위치 좌표 저장 및 중간위치까지의 거리 계산
- RabbitMQ를 메시지 브로커로 채택
- TopicExchange를 사용하여 Group으로 Binding 하여 그룹원 별 queue 사용
- 정해진 패턴에 맞게 Group의 DB PK를 기준으로 TopicExchange 사용으로 부하 분산
- 동적으로 queue, binding을 생성하고 Connection이 없다면 자동 삭제되어 불필요한 리소스 사용하는 케이스 제거
- 효율적으로 좌표 저장 및 거리 계산 가능했으며 결합도 낮은 아키텍처 구성
실시간 통신 기술 성능테스트 관련 포스트:
https://ohksj77.tistory.com/267
실시간 통신 기술 상호 비교 및 분석 with k6 성능테스트
이길저길의 실시간 양방향 위치 공유 시스템 설계 과정에 수행한 성능테스트 결과를 공유하고자 한다. 시스템의 요구사항은 간략하게 다음과 같다:각 클라이언트는 연결이 된 시점부터 3초에
ohksj77.tistory.com
'프로젝트-탐구 > 이길저길' 카테고리의 다른 글
| 전략 패턴 기반 테스트 더블을 이용한 단위 테스트 (0) | 2024.03.25 |
|---|---|
| Resilience4j 적용과 모니터링까지 (0) | 2024.03.25 |
| Redis Cache 적용과 만료 전략 수립 (0) | 2024.03.25 |
| RabbitMQ 비동기 처리와 데드레터 처리 적용기 (0) | 2024.03.25 |
| FULL Text Index 적용기 (0) | 2024.03.25 |