
티스토리 뷰
GitHub: https://github.com/ohksj77/kmysql
GitHub - ohksj77/kmysql: Kotlin으로 만든 MySQL 프로젝트
Kotlin으로 만든 MySQL 프로젝트. Contribute to ohksj77/kmysql development by creating an account on GitHub.
github.com
👋🏻 들어가며
이전에 응시한 면접에서 이러한 질문을 받은 적이 있습니다.
“직접 DB를 구현한다면 어떻게 Repeatable Read를 구현하고 싶으신가요?”
당시 질문을 받은 후 추상적인 생각들만 겉돌며 당황한 기억이 있습니다.
이러한 계기로 언젠가는 간단하게라도 DBMS를 구현해보고 싶은 욕구가 생겼고, 이를 실제로 구현해봤습니다.
기술 스택: Kotlin 1.9+, Java 17+, Gradle 8.0+
언어나 빌드 툴은 다양한 선택지가 있지만, 성능 등의 이점 보다는 자주 사용 중인 기술로 선정해 진행했습니다.
📌 동작 예시

🏗️ KMySQL의 핵심 컴포넌트들
전체 아키텍처 개요
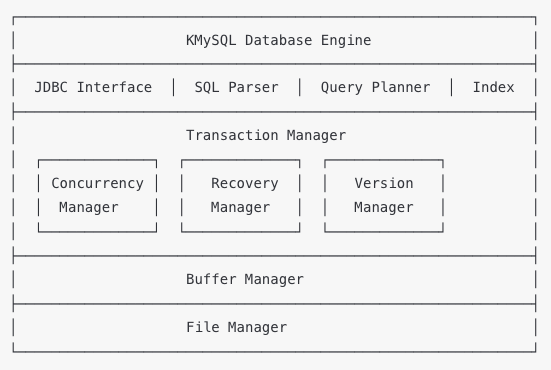
각 컴포넌트의 역할
- File Manager: 디스크 I/O 관리, 페이지 and 블록 단위 파일 접근
- Buffer Manager: 메모리 캐싱, LRU 기반 버퍼 교체
- Transaction Manager: ACID 보장, 동시성 제어, 복구 관리
- Index Manager: B-Tree, Hash 인덱스 관리
- Query Planner: SQL 실행 계획 생성 및 최적화
- JDBC Interface: 외부 애플리케이션 연동
🔄 트랜잭션 관리: ACID의 핵심
ACID 속성 개념과 구현 방식
원자성 (Atomicity)
- 모든 작업이 성공하거나 모두 실패해야 함
- 로그 기반 복구로 롤백 보장
일관성 (Consistency)
- 데이터베이스가 항상 유효한 상태 유지
- 제약조건과 트리거로 보장
격리성 (Isolation)
- 동시 실행되는 트랜잭션들이 서로 간섭하지 않음
- MVCC와 락킹으로 구현
지속성 (Durability)
- 커밋된 트랜잭션은 영구적으로 저장
- WAL(Write-Ahead Logging) 프로토콜로 보장
격리 수준과 동시성 제어
격리 수준별 동시성 vs 일관성 트레이드오프
READ UNCOMMITTED ←─── 높은 동시성, 낮은 일관성
READ COMMITTED
REPEATABLE READ
SERIALIZABLE ←─── 낮은 동시성, 높은 일관성
MVCC (Multi-Version Concurrency Control)
- 각 트랜잭션이 데이터의 특정 시점 스냅샷을 보게 함
- 읽기 작업이 쓰기 작업을 블록하지 않음
- 메모리 사용량과 성능 간의 균형
💾 버퍼 관리: 성능 최적화의 핵심
메모리 계층 구조
CPU Cache (L1, L2, L3)
↓ (10-100배 빠름)
Main Memory (Buffer Pool)
↓ (100,000-1,000,000배 빠름)
Disk Storage
버퍼 관리 전략
LRU (Least Recently Used) 교체 정책
- 가장 오래전에 사용된 페이지를 먼저 교체
- 지역성 원리(locality)를 활용한 성능 최적화
핀/언핀 메커니즘
- 페이지가 사용 중일 때는 교체되지 않도록 보호
- 참조 카운트로 안전한 메모리 해제 보장
지연 쓰기 (Lazy Writing)
- 변경된 페이지를 즉시 디스크에 쓰지 않음
- 버퍼가 가득 찰 때나 체크포인트 시에만 쓰기
🗂️ 인덱스: 검색 성능의 핵심
인덱스의 종류와 특징
B-Tree 인덱스
- 범위 검색과 정렬에 최적화
- 삽입/삭제 시 자동으로 균형 유지
- 검색 시간: O(log n)
Hash 인덱스
- 등호 검색에 최적화
- 매우 빠른 검색 속도: O(1)
- 범위 검색은 비효율적
💾 로그 기반 복구: 데이터 안정성의 보장
WAL (Write-Ahead Logging) 기법
핵심 원칙: 데이터 페이지를 디스크에 쓰기 전에 로그를 먼저 써야 함
트랜잭션 실행 순서:
1. 로그 레코드 작성
2. 로그를 디스크에 강제 쓰기 (flush)
3. 데이터 페이지 수정
4. 커밋 로그 작성
5. 커밋 로그를 디스크에 강제 쓰기
복구 시나리오
시스템 크래시 복구
- 마지막 체크포인트부터 로그를 재실행 (REDO)
- 커밋되지 않은 트랜잭션 롤백 (UNDO)
트랜잭션 실패 복구
- 해당 트랜잭션의 로그를 역순으로 읽어서 변경사항 되돌리기
🔍 쿼리 처리: SQL에서 결과까지
쿼리 처리 파이프라인
SQL 쿼리
↓
Lexical Analysis (토큰화)
↓
Parsing (구문 분석)
↓
Semantic Analysis (의미 분석)
↓
Query Optimization (최적화)
↓
Execution Plan (실행 계획)
↓
Query Execution (실행)
↓
Result Set (결과)
실행 계획의 종류
- Table Scan: 전체 테이블을 순차적으로 읽기
- Index Scan: 인덱스를 사용한 효율적인 검색
- Nested Loop Join: 중첩 루프를 이용한 조인
- Hash Join: 해시 테이블을 이용한 조인
- Sort Merge Join: 정렬 후 병합하는 조인
🌭 실제 사용 시나리오
대화형 SQL 클라이언트
-- 데이터베이스 연결
Connect> kmysql_db
-- 테이블 생성 및 데이터 삽입
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(100)
);
INSERT INTO users VALUES (1, '홍길동', 'hong@example.com');
INSERT INTO users VALUES (2, '김철수', 'kim@example.com');
-- 트랜잭션 내에서 작업
BEGIN;
UPDATE users SET name = '김영희' WHERE id = 2;
SAVEPOINT sp1;
DELETE FROM users WHERE id = 1;
ROLLBACK TO SAVEPOINT sp1;
COMMIT;
JDBC를 통한 프로그래밍
// 데이터베이스 연결
val driver = EmbeddedDriver()
val connection = driver.connect("kmysql_db", null)
try {
connection.setAutoCommit(false) // 트랜잭션 시작
val statement = connection.createStatement()
statement.executeUpdate("INSERT INTO users VALUES (3, '이철수', 'lee@example.com')")
val resultSet = statement.executeQuery("SELECT * FROM users WHERE id = 3")
while (resultSet.next()) {
println("Name: ${resultSet.getString("name")}")
}
connection.commit() // 트랜잭션 커밋
} catch (e: Exception) {
connection.rollback() // 오류 시 롤백
throw e
} finally {
connection.close()
}
💯 성능과 안정성 테스트
동시성 테스트
여러 트랜잭션이 동시에 실행될 때:
- 데드락 감지: 무한 대기 방지
- 락 타임아웃: 일정 시간 후 자동 롤백
- 격리 수준별 동작: 각 격리 수준에서의 일관성 보장
복구 테스트
시스템 크래시 시나리오:
- 체크포인트 복구: 마지막 체크포인트부터 복구
- 로그 재실행: 커밋된 트랜잭션 재실행
- 롤백 복구: 미커밋 트랜잭션 롤백
🚶🏻 향후 발전 방향
- 현재는 Embedded DB 로만 동작할 수 있기에 단독 DB 서버로서 동작할 수 있도록 발전시키고 싶습니다.
- 현재는 서버 내부에서 파일 시스템을 활용해 동작 중입니다.
- 세부 구현들이 아직 실제 DBMS 수준에 미치지 못한 경우가 있어서 보완하고 싶습니다.
🤝🏻 Maven & Gradle 배포


- Maven Repository에 Public하게 배포하는 방법은 절차가 다소 길기에 GitHub Package로 우선 배포해보았습니다.
👍🏻 후기
- 상상만 하지 않고 실현했다는 점이 가장 의미 깊었습니다.
- 그 외로 DBMS의 내부 구현에 대해 더 깊게 알게 되었고, 상용 DBMS 제품들은 정말 많은 고민이 들어간 시스템이라는 것을 다시 한 번 깨닫게 되었습니다.
'오픈소스-직접-구현' 카테고리의 다른 글
| Kotlin으로 API Gateway 따라 만들기 (0) | 2025.07.07 |
|---|---|
| Kotlin으로 Git 따라 만들기: KGit (0) | 2025.07.06 |